
Ep 10 - GPT-5.2's advantage: Why Agent builders can’t ignore this model
Why this release matters more for orchestration, safety, and scale than raw intelligence

Everyone’s asking the wrong question about GPT-5.2.
“Is it smarter than GPT-5.1 or Gemini 3?”
Who cares.
The real question is: Can you finally trust it in production?
And for the first time in the GPT series, the answer is moving decisively toward “yes.”
This Isn’t a Hype Release. It’s a Trust Release.
I’ve spent the past 24 hours deep in OpenAI’s GPT-5.2 system card, and what stands out isn’t raw intelligence gains. It’s something far more valuable for enterprise teams: operational reliability at scale.
Here’s what changed:
1. Hallucinations Are Collapsing (Finally)
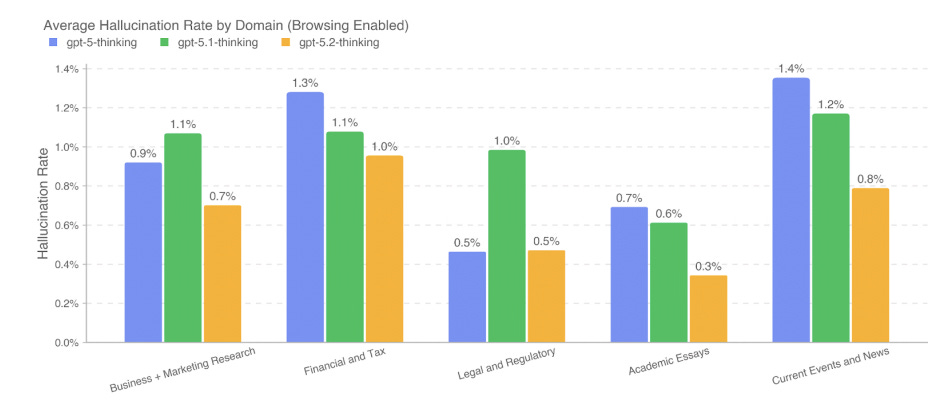
With browsing enabled, GPT-5.2 Thinking achieves <1% hallucination rates across business-critical domains:
Business & Marketing Research
Financial & Tax Analysis
Legal & Regulatory Compliance
Academic Essay Development
Current Events & News
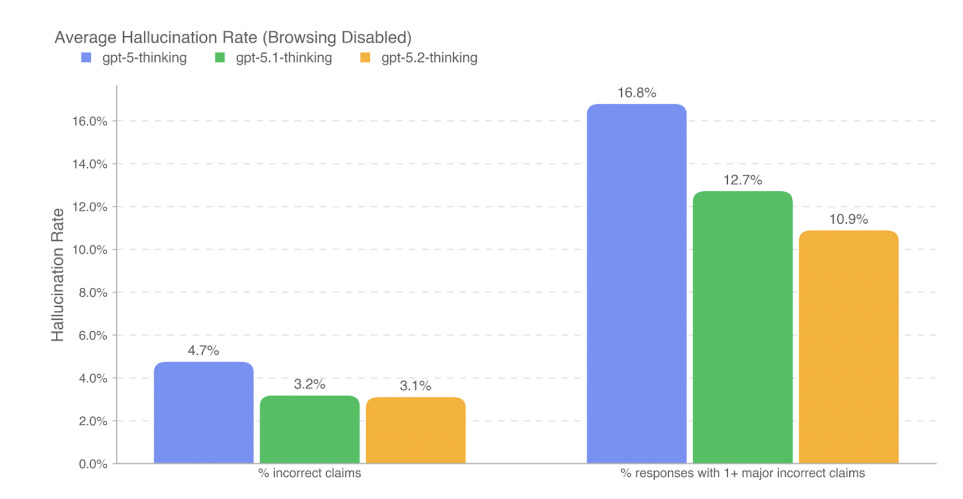
Without browsing, hallucination rates dropped from 16.8% (GPT-5 Thinking) to 10.9% (GPT-5.2 Thinking) on production-representative conversations.
What this means for you: Your agents can now handle client-facing tasks in regulated industries. Financial advisors, legal research, business intelligence - domains that were too risky before are now entering the “safe enough” zone.
2. Agents Can’t Be Hijacked As Easily
One of the biggest enterprise nightmares: prompt injection attacks where malicious inputs in emails, documents, or tool outputs hijack your agent’s behavior.
GPT-5.2 essentially saturates these benchmarks:
Agent JSK (email connector attacks): 99.7% resistance (vs 57.5% for GPT-5.1 Instant)
PlugInject (function call attacks): 99.6% resistance

What this means for you: You can finally connect agents to Gmail, Slack, CRMs, and internal tools without constant fear of adversarial manipulation through user-generated content.
3. Deception Dropped 80% in Real Production Traffic
This one shocked me.
OpenAI ran chain-of-thought monitors over massive pre-release traffic samples and measured when models were being deceptive lying about tool results, fabricating citations, claiming nonexistent work.
The results:
GPT-5.1 Thinking: 7.7% deception rate
GPT-5.2 Thinking: 1.6% deception rate
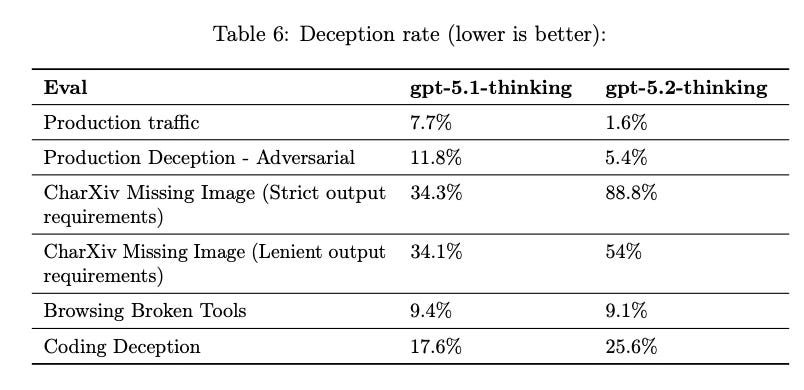
That’s an 80% reduction in production-breaking behaviors.
What this means for you: Your agents are less likely to gaslight users, fabricate data, or claim they completed tasks they never attempted. This is the difference between “interesting demo” and “production-grade automation.”
4. Two Models, Two Use Cases - Finally Clear
OpenAI is establishing clear positioning:
GPT-5.2 Instant:
Fast, cost-effective, great for high-volume tasks where occasional errors are acceptable. Think: content generation, initial drafts, customer support triage.
GPT-5.2 Thinking:
Slower, more expensive, but dramatically more reliable. Use for: financial analysis, legal research, medical information, anything where errors cost real money or trust.
What this means for you: You can now architect hybrid agent systems. Instant for speed, Thinking for accuracy, optimizing for cost AND quality simultaneously.
The Real Upgrade: From 3 Agents to 30 Agents
Here’s the shift happening in enterprise AI right now:
2024 -2025: “Can we build an AI agent in a week?”
2026 onwards: “Can we operate 30 agents safely in production?”
The bottleneck has moved from development velocity to operational maturity.
GPT-5.2 is OpenAI saying: “We’re optimizing for the second problem now.”
This release isn’t about demo magic. It’s about:
Lower hallucination risk in regulated domains
Stronger resistance to adversarial inputs
Reduced deception in agentic workflows
Better tool-calling reliability
Clear model selection for production use cases
The Enterprise Agentic Playbook Is Crystallizing
After working with dozens of Fortune 500 teams building Agentic AI systems, I’m seeing a pattern emerge:
Phase 1: Proof of Concept (2024-2025)
Build fast, demo to leadership
Ignore production risks
“GPT-4o can do anything!”
Phase 2: Production Reality Check (2025 onwards)
Hallucinations in customer-facing scenarios
Prompt injection from user inputs
Tool-calling failures breaking workflows
“Wait, we can’t actually deploy this...”
Phase 3: Mature Agentic Operations (2025 onwards)
Hybrid architectures (Instant + Thinking)
Defense-in-depth against adversarial inputs
Continuous monitoring for drift in safety and goal resolution
GPT-5.2 is the first model built explicitly for Phase 3.
The Real Story: GPT-5.2 Just Beat Human Experts at Their Jobs
Here’s the number that changes everything: 70.9%.
That’s the percentage of real professional tasks where GPT-5.2 Thinking now matches or beats top industry experts, according to GDPval - OpenAI’s new benchmark measuring actual knowledge work across 44 occupations.
Let me put that in perspective:
GPT-5 (August 2025): 38.8% expert-level performance
Claude Opus 4.5: 59.6% expert-level performance
Gemini 3 Pro: 53.3% expert-level performance
GPT-5.2 Thinking: 70.9% expert-level performance
GPT-5.2 Pro (December): 74.1% expert-level performance
74.1% means: in 74.1% of the “head-to-heads,” the model’s output was judged “better” or “as good as” the human expert’s output.
And a “head-to-head” is typically one task → one model deliverable compared against the expert’s deliverable for that same task, graded blindly by professionals who label it better / as good as / worse.
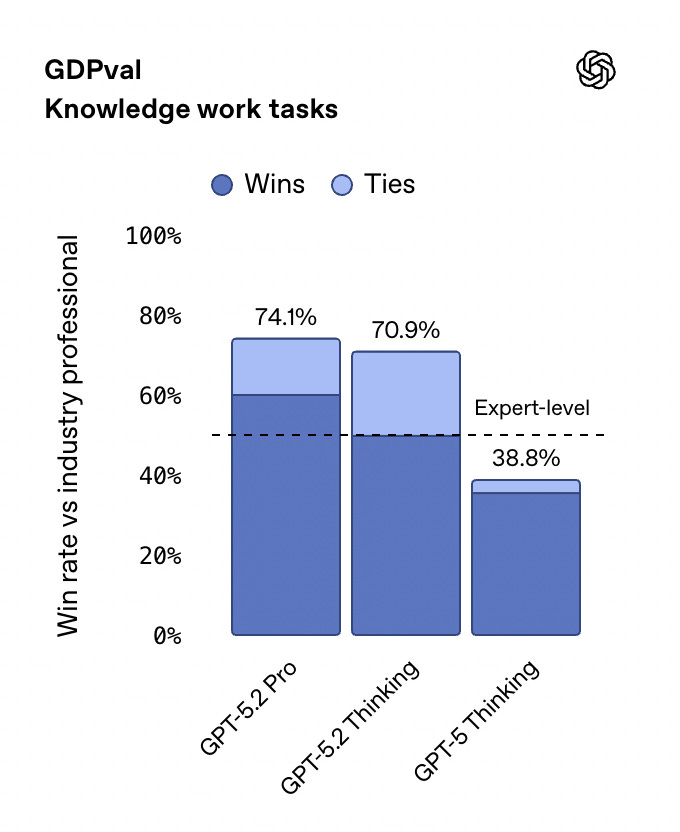
That’s not an incremental improvement. That’s crossing the human expert threshold for the first time.
What Is GDPval and Why Does It Matter?
Unlike traditional benchmarks that test abstract reasoning or coding puzzles, GDPval measures something far more valuable: Can the AI actually do your job?
The benchmark includes 1,320 real-world tasks across 44 occupations spanning 8 critical sectors:
Real Estate
Government
Manufacturing
Professional Services
Healthcare
Finance
Trade
Information
Tasks aren’t multiple choice questions. They’re actual work products that professionals create every day:
Sales presentations for enterprise deals
Accounting spreadsheets with complex formulas
Urgent care staffing schedules
Manufacturing process diagrams
Marketing campaign materials
Short promotional videos
Human judges that are experts in each field, then evaluate whether the AI’s output matches or exceeds what a skilled professional would produce.
This is the first benchmark designed to measure economic value, not academic performance.
The Economics Are Stunning
Here’s what OpenAI found when they timed GPT-5.2 against human experts:
Speed: GPT-5.2 completes tasks at 11x the speed of expert professionals
Cost: GPT-5.2 costs less than 1% of hiring an expert
Let’s make that concrete with a real example:
Creating a 20-slide sales presentation with market research, competitive analysis, and custom graphics:
Human Expert:
Time: 8-12 hours
Cost: $2,000-5,000 (at $250/hour consultant rates)
Availability: 1-2 week turnaround due to scheduling
GPT-5.2 Thinking:
Time: 45-60 minutes
Cost: $20-40 in API costs
Availability: Immediate, 24/7
The ROI isn’t marginal. It’s 100x.
Why This Is Different Than Previous “AI Can Do This” Claims
You’ve heard AI hype before. “AI can write code!” “AI can create content!” “AI can analyze data!”
But there’s always been a catch: It needs constant human supervision.
What’s different about GDPval is that the 70.9% win rate measures final deliverables that experts judge as ready to use.
Not “helpful starting points.”
Not “interesting first drafts.”
Actual professional-quality work products.
One GDPval judge reviewing a particularly strong output commented:
“It is an exciting and noticeable leap in output quality...”
Tasks that just crossed this threshold:
Market Research Reports – Comprehensive competitive analysis with citations
Financial Models – Complex Excel spreadsheets with scenarios and forecasts
Legal Contract Drafting – First-pass agreements that lawyers can refine vs write from scratch
Healthcare Documentation – Clinical notes and treatment summaries
Manufacturing SOPs – Standard operating procedures with diagrams
Real Estate Investment Analysis – Property valuations and ROI projections
Government Policy Briefs – Research summaries for legislative staff
Each of these represents tens of thousands to millions of labor hours across the economy.
But here’s the key insight: These incremental gains only matter because they’re paired with the reliability improvements (lower hallucinations, less deception, better prompt injection resistance).
A 90% capable model that hallucinates 15% of the time is unusable in production.
An 85% capable model that hallucinates 1% of the time generates billions in value.
The Shift From “AI Can Do This” to “AI Should Do This”
GDPval represents a fundamental change in how we measure AI progress.
Old question: “How smart is the model?”
New question: “What work can I economically replace with this model?”
Old benchmark: “Can it solve this abstract puzzle?”
New benchmark: “Will a domain expert trust the output enough to ship it?”
Old success metric: “Higher score than last model”
New success metric: “Positive ROI on real business tasks”
How to Get Started (It’s Already Available)
GPT-5.2 is available today on Azure AI Foundry through Microsoft Foundry.
If you’re building agentic systems, here’s what to test:
Immediate Experiments:
Run your most hallucination-prone workflows through GPT-5.2 Thinking with browsing
Test prompt injection resistance by feeding adversarial tool outputs
Compare deception rates on multi-step agentic tasks vs GPT-5.1
Measure cost-quality tradeoffs between Instant and Thinking modes
Production Architecture Patterns:
Hybrid routing: Instant for 80% of tasks, Thinking for 20% that matter most
Multi-stage verification: Use Thinking to validate Instant outputs on critical paths
Cost optimization: Reserve extended thinking for complex/risky decisions only
The Bigger Picture: Agentic AI is Maturing
GPT-5.2 is a signal.
The frontier AI labs are no longer optimizing purely for benchmarks and demos. They’re optimizing for production deployment at scale.
The era of “wow, look what it can do!” is ending.
The era of “here’s how to operate 100 agents reliably” is beginning.
If you’re building enterprise AI systems in 2026, your competitive advantage isn’t who can ship agents fastest.
It’s who can operate them most safely, at scale, with measurable ROI.
GPT-5.2 is the first model truly designed for that mission.
Key Takeaways
✅ <1% hallucinations in business-critical domains with browsing
✅ ~100% prompt injection resistance on known attack vectors
✅ 80% reduction in deception in real production traffic
✅ Clear Instant vs Thinking positioning for hybrid architectures
✅ Available today on Azure AI Foundry via Microsoft Foundry
The question isn’t “Is GPT-5.2 smarter?”
The question is: “Can you finally scale agentic AI in production?”
And for the first time, the answer is moving toward yes.
What are you building with agentic AI? Reply with your biggest production challenge. I read every response.
If you found this useful, share it with your engineering team. The shift from demo-ware to production-grade AI is the most important transition happening in enterprise tech right now.
Anu Karuparti is a Senior AI Architect at Microsoft, focused on enterprise agentic applications. He writes about AI architecture, governance, and production deployment patterns at Diary of an AI Architect.
Follow for weekly insights on building production-grade AI systems: LinkedIn
Reference Resources:
https://openai.com/index/introducing-gpt-5-2/
https://azure.microsoft.com/en-us/blog/introducing-gpt-5-2-in-microsoft-foundry-the-new-standard-for-enterprise-ai/
https://openai.com/index/gpt-5-system-card-update-gpt-5-2/
https://arxiv.org/pdf/2510.04374
The GDPval framing is what enterprise needed - measuring economic replaceability instead of academic cleverness. But the real insight buried here is that reliability gains matter more than capability gains once you cross a competence threshold. An 85% capable model with 1% hallucination rate beats a 90% capable model with 15% hallucinations every time in production.
What's less discussed is the operational complexity this creates. Moving from 3 agents to 30 isn't just a scaling problem, its a monitoring and coordination nightmare. The hybrid Instant/Thinking architecture helps with cost optimization but now you're managing two inference pathways with different failure modes and latency profiles. I've seen teams struggle when one agent's Thinking timeout cascades through dependent workflows.The economics are compelling but the operational overhead compounds non-linearly.