
#13 - Generalized vs Specialized AI
Why one-size-fits-all agents break in production, and how multi-agent systems solve the problem

It’s 11 PM. Catherine’s Tokyo flight has been delayed three hours.
She’ll miss her connection. She opens her airline’s chat: “My flight is delayed 3 hours and I’ll miss my connection to Tokyo. Can you rebook me?”
Twenty seconds later, an AI Agent suggests a route with a 14-hour layover. There’s a better option with just 2 hours that it completely missed. It confirms the rebooking but never mentions her business class upgrade won’t transfer. She’ll find out at the gate tomorrow morning.
The same system answered her earlier questions instantly. “Is my flight delayed?” “What’s my gate number?” Answers in two seconds.
But the moment she needed help with a real problem. One that touched multiple systems, it broke down.
This isn’t a prompt engineering problem. You can’t fix it with better examples or a longer system prompt.
The problem is architectural: one model trying to coordinate multiple data sources and perform distinct operations simultaneously.
Think of a busy restaurant. You could have one cook trying to prep ingredients, work the grill, make desserts, and handle orders all at once. They’d do a mediocre job at everything. Or you could have a prep cook, a line cook, and a pastry chef. Each focused on what they do best. Orders move faster, and the food tastes better.
This is the fundamental choice in AI systems: use one model that handles everything, or break tasks into specialized components.
Why Single Agents Hit a Wall
Consider an e-commerce inquiry: “My order #12345 hasn’t arrived, and I noticed you charged me twice. Also, can you recommend similar products?”
You’re asking one LLM to manage order tracking, payment processing, and product recommendations simultaneously. Three entirely different jobs requiring distinct skills.
What happens? The model loses context while switching between tasks.
Information drops. Errors compound. You get mediocre results across all three tasks.
Multi-agent approach: Split the inquiry across specialized agents.
Order Tracking Agent checks logistics databases with shipping-specific prompts.
Billing Agent reviews transactions with financial optimizations.
Recommendation Agent analyzes purchase patterns without getting pulled into payment disputes.
Each agent excels at its task while maintaining focused context that reduces hallucinations.
But here’s the real advantage: using different agents gives model selection flexibility.
Your Math Agent uses GPT-5-pro reasoning model for reliable calculations.
Your Creative Agent uses GPT-4.1 at 0.9 for marketing copy.
Your Summary Agent runs on GPT-4o-mini to cut costs.
You match tools to tasks instead of forcing one model to handle everything.
The math is compelling. If 80% of queries are simple FAQs, why send them to expensive reasoning models? Route them to lightweight models costing 1/100th as much. Save premium models for the 5% of queries needing complex reasoning.
This is how production systems achieve 60% cost reductions while maintaining quality.
The Validation Problem
Marcus is presenting to the CFO when she interrupts: “That number seems high. Q3 last year was $10 million, this year $13 million. That’s 30% growth, not 45%.”
His stomach drops.
The AI had compared Q3 this year to Q1 last year. An obvious error, but one it stated with complete confidence.
No asterisk, no “verify this” warning. Just authoritative
wrongness.
Even the best models make mistakes. Single agents have no mechanism for self-correction.
When they generate wrong information, they sound just as confident as when they’re right.
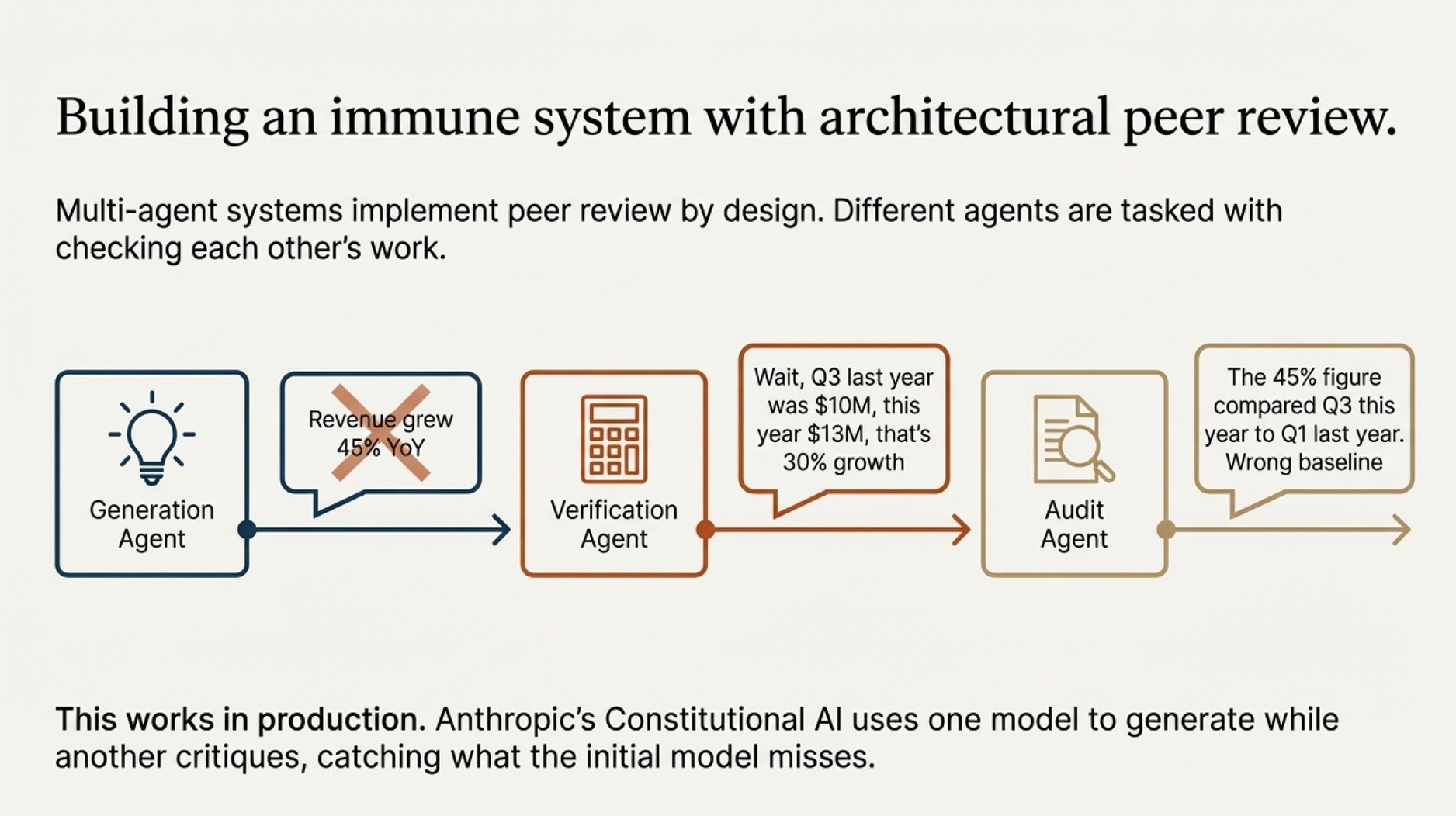
Multi-agent systems implement peer review architecturally:
Generation Agent creates initial response: “Revenue grew 45% YoY”
Verification Agent recalculates independently: “Wait Q3 last year was $10M, this year $13M, that’s 30% growth”
Audit Agent investigates: “The 45% figure compared Q3 this year to Q1 last year. Wrong baseline”
The system self-corrects through peer review. Logic Agent checks reasoning consistency. Fact Agent verifies claims against source data.
This approach works in production. Anthropic’s Constitutional AI demonstrates it. One model generates while another critiques based on constitutional principles. The critique-revision loop catches what the initial model misses.
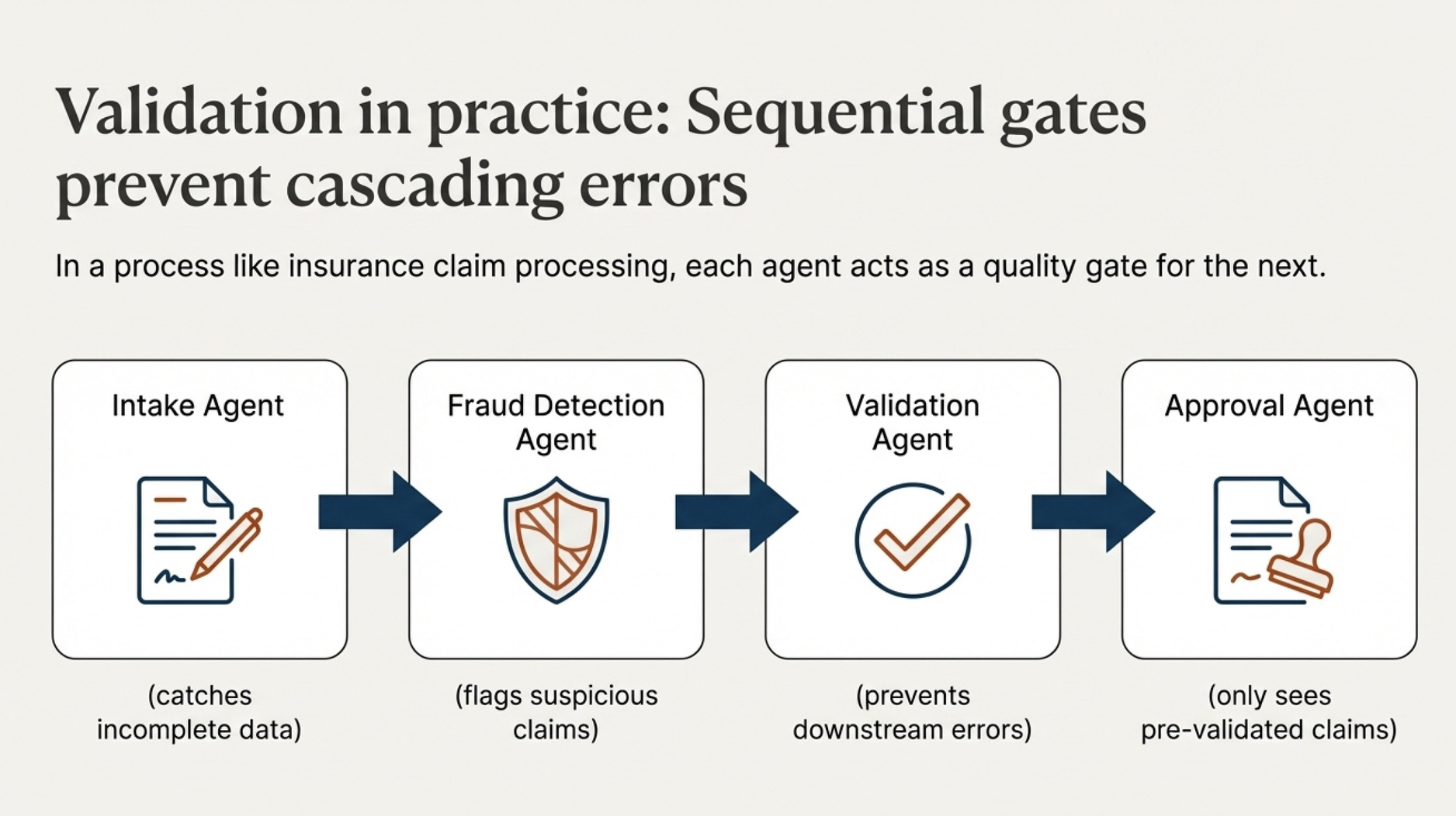
Sequential validation gates prevent errors from cascading.
For example, in insurance claim processing:
The Speed Bottleneck
It’s Monday morning. Your product team launched a new feature, and 2,000 customer feedback responses flooded in over the weekend. Your CEO wants insights by the 10 AM leadership meeting. 90 minutes away.
You feed everything to your AI agent. It analyzes the first review... then the second... then the third. Twenty minutes in, it’s processed 50 reviews. At this rate, you’ll have results by Wednesday.
But there’s a worse problem. By review #50, the AI has forgotten patterns from review #5. Its context window fills with processed text, pushing out insights. You’ll get 2,000 individual summaries but miss the critical finding: 40% of complaints mention the same onboarding bug.
Multi-agent approach:
Dispatcher Agent splits reviews into batches
10 Analysis Agents process 10 reviews each simultaneously
Aggregator Agent combines results into final report
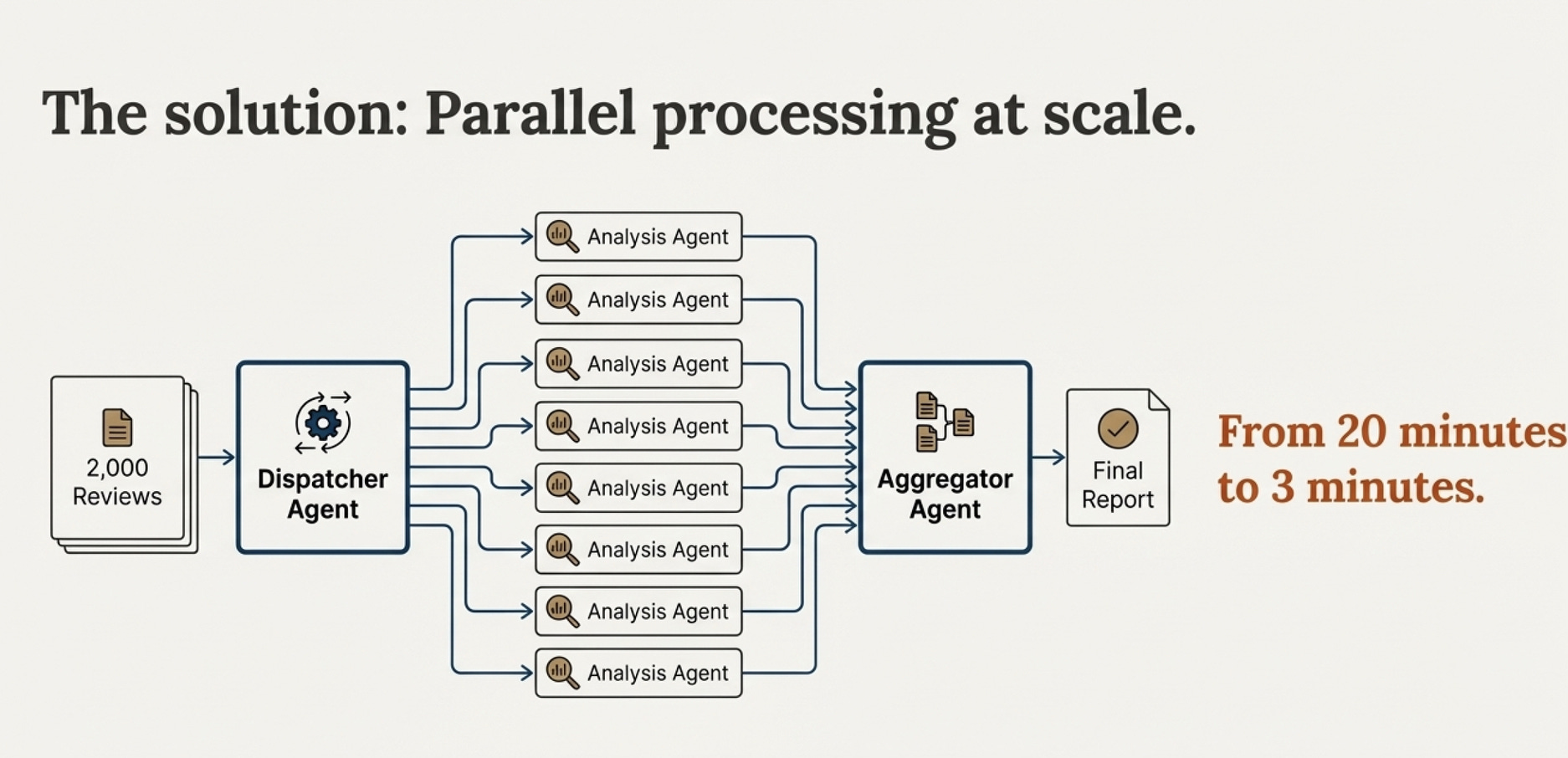
You go from 20 minutes to 3 minutes. And when agents work in parallel, they spot patterns across all reviews that a single model would miss.
GitHub Copilot in VS Code demonstrates this. When you rename a function, it simultaneously updates the definition, every place it’s called across files, and the corresponding tests. One agent per task, all working in parallel. What used to take 30 minutes now happens in seconds.
Fault Tolerance
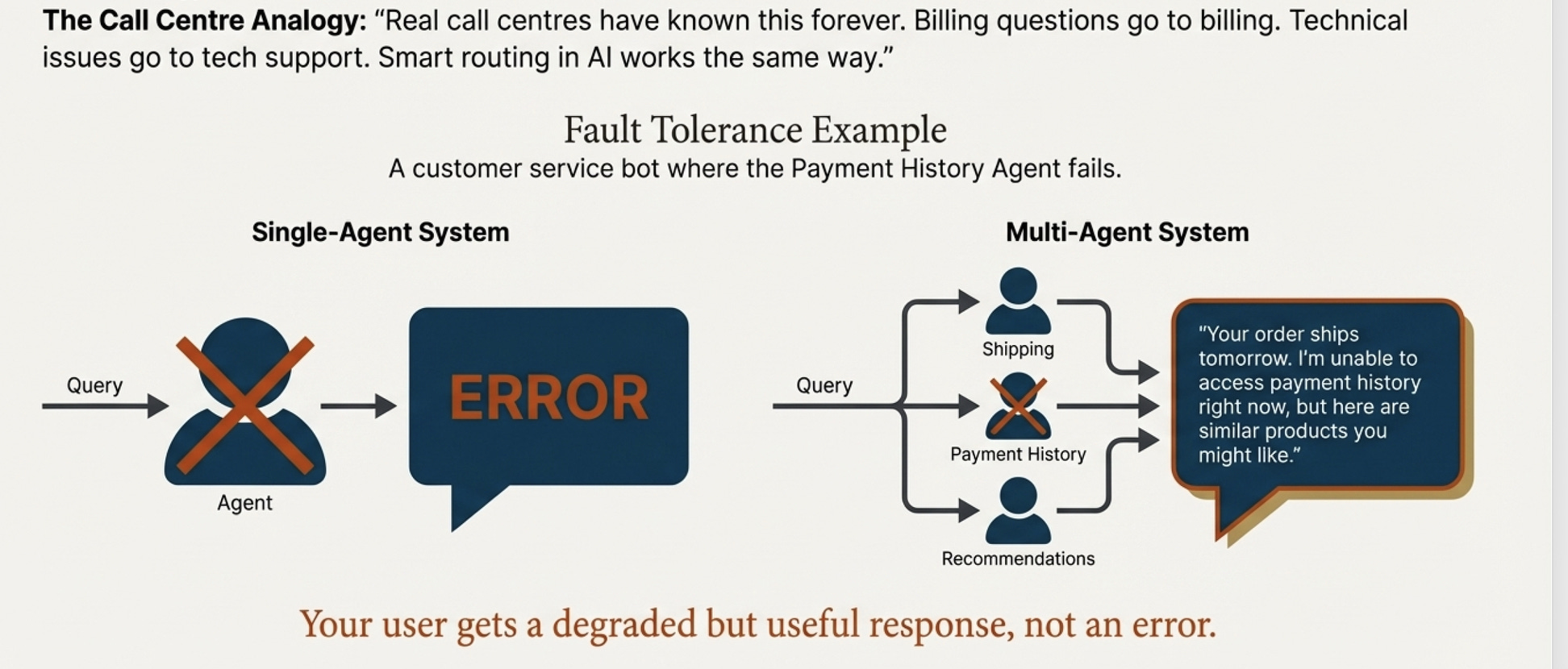
In single-agent systems, one failure brings down your entire workflow. Multi-agent systems handle this differently.
Consider customer service where the Payment History Agent fails due to database maintenance.
In a single-model system, the entire interaction fails.
In a multi-agent system, you still provide shipping updates and product recommendations. The response acknowledges the limitation: “Your order ships tomorrow. I’m unable to access payment history right now, but here are similar products you might like.”
This graceful degradation ensures users always receive value, even when parts of your system experience issues.
If an agent keeps failing, the system implements fallback strategies:
Primary Analysis Agent times out → Switch to Backup Analysis Agent
Backup also fails → Return cached results with staleness warning
Your user gets a degraded but useful response, not an error.
Smart Routing
Not all customer calls are the same. And treating them like they are is how support teams burn out and customers get mad. Think about calling customer support yourself.
If all you need is:
“What are your business hours?”
You don’t expect to talk to a senior engineer. You just want a fast, clear answer and to move on with your life.
But if you’re calling because:
“Your latest update broke our integration and our systems are down”
That’s not a chatbot moment. That’s an “I need help now” moment. Real call centers have known this forever.
Billing questions go to billing. Technical issues go to tech support. Angry or frustrated customers get routed to someone who knows how to calm things down before fixing the problem.
Smart routing in AI works the same way.
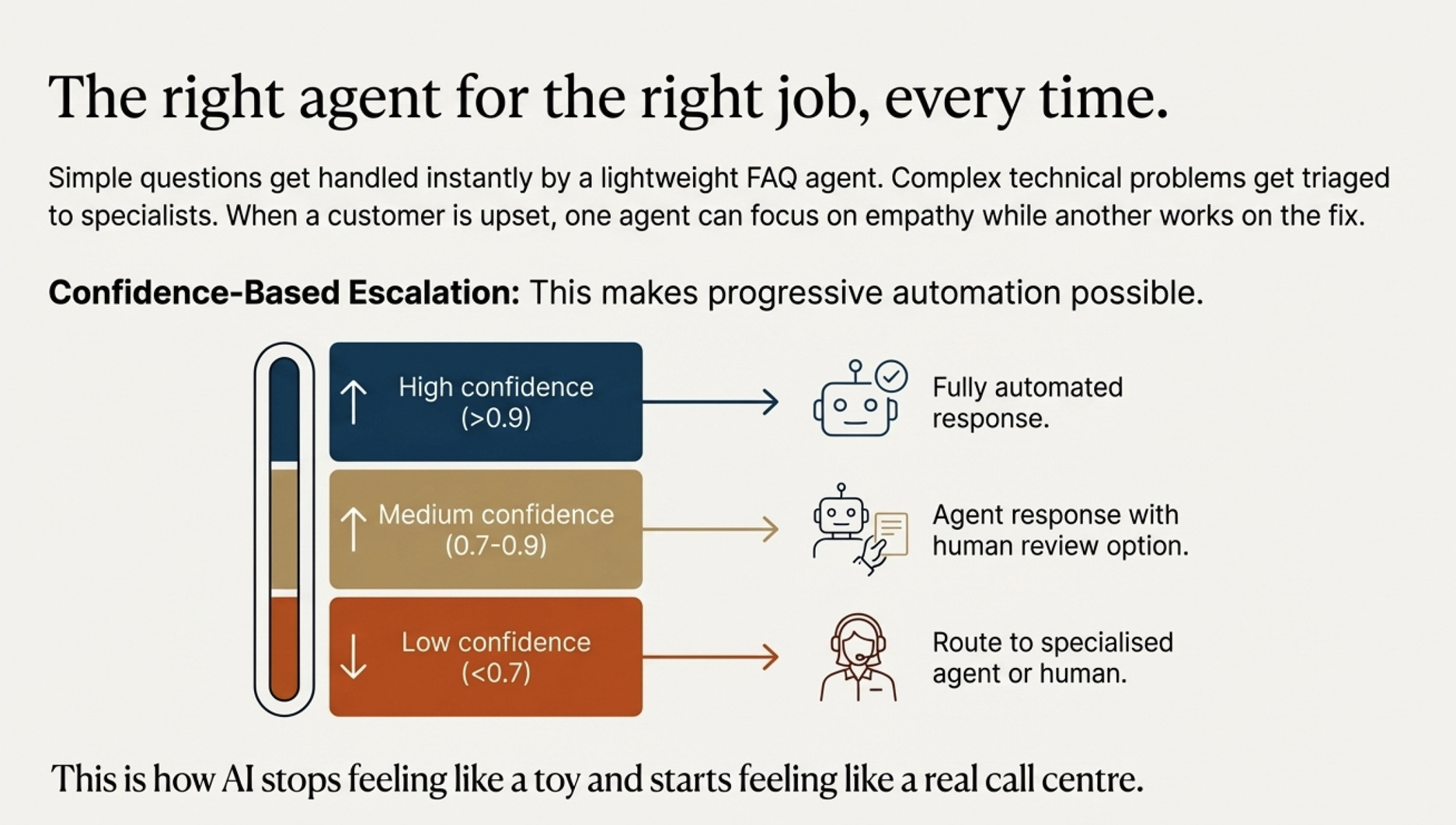
Simple questions get handled instantly by a lightweight FAQ agent using cached answers.
Account or billing issues go to agents that know your history and can resolve things quickly.
Complex technical problems get triaged, then passed to specialists who actually understand what’s going on.
And when someone’s upset, one agent focuses on empathy while another works on the fix.
The point is to make sure the right agent shows up.
That’s how support stays fast. That’s how costs stay under control.
And that’s how AI stops feeling like a toy and starts feeling like a real call center.
Confidence-based escalation makes progressive automation possible:
High confidence (>0.9): Fully automated response
Medium confidence (0.7-0.9): Agent response with human review option
Low confidence (<0.7): Route to specialized agent or human
You adjust gradually instead of going all-or-nothing with automation. Start conservative, increase thresholds as you gather data.
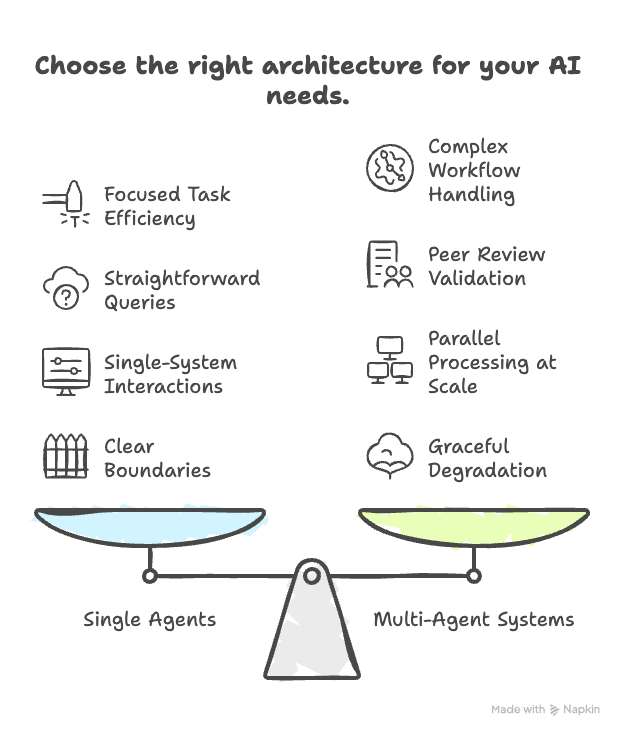
Multi-agent systems aren’t just “better” than single agents. They’re architecturally different solutions to fundamentally different problems.
Single agents excel at: Focused tasks with clear boundaries, straightforward queries, single-system interactions.
Multi-agent systems excel at: Complex workflows requiring specialization, validation through peer review, parallel processing at scale, graceful degradation under failure.
The companies shipping reliable AI products aren’t just using bigger models.
They’re using teams of specialized agents that work together, each handling what they do best.
If there’s one takeaway here, it’s this: most AI systems fail not because the models are weak, but because the architecture asks one model to do too much.
Specialization isn’t an optimization. It’s a prerequisite for reliability at scale.
Once you start thinking in agents, routing, validation, and fallback stop feeling complex. They start feeling obvious.
Further reading (highly recommended):
If you want a deeper architectural breakdown of how real multi-agent systems are designed and evaluated in production, this whitepaper from Galileo is worth your time. It covers agent coordination patterns, validation strategies, and the tradeoffs teams run into once they move beyond demos.
Mastering Multi-Agent Systems
https://galileo.ai/mastering-multi-agent-systems
If this helped you think differently about AI architecture, feel free to share it with someone building or deploying AI systems right now.
I also host a subscriber chat where I share practical architecture frameworks, templates, and resources to help you build production-ready agentic AI systems.
